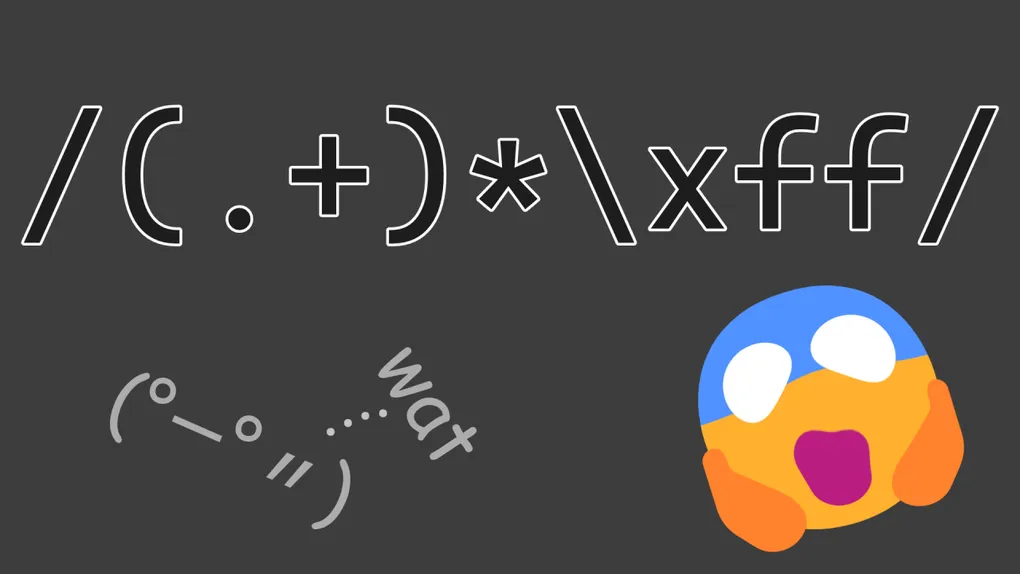
UofTCTF 2025 - CodeDB
Moving all of my past CTF write-ups to this website…
This was the challenge I was most happiest to complete because, spoiler alert: it was my first change to perform a timing attack! Or at least the first one I’ve done successfully 🤔. To be fair, it’s probably the easiest timing attack one can pull off, as we’ll see soon, but I’m just happy to have finally done one.
Challenge
The website is pretty simple:
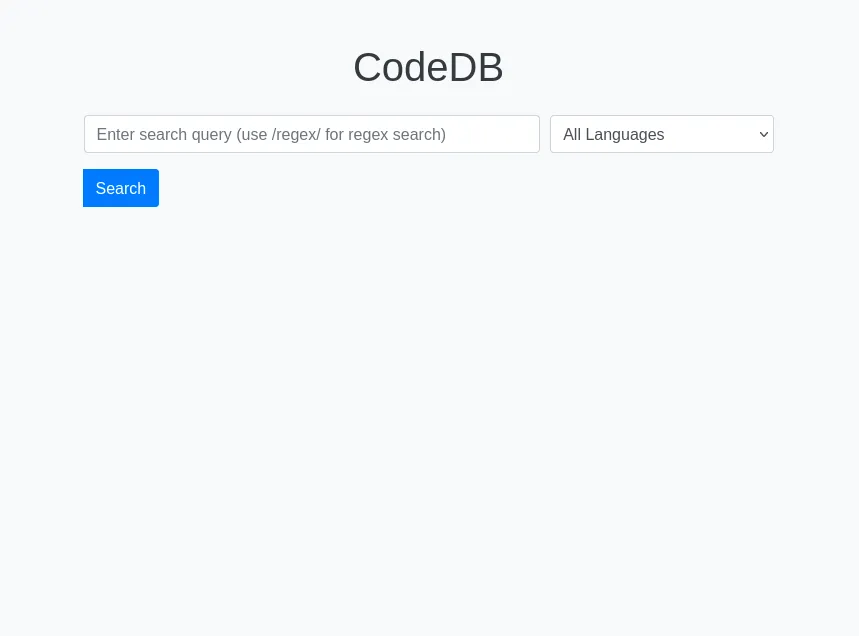
Analysis
The project contains three things of interest:
- A
code_samplesfolder with aflag.txt - An
app.js— a Node.js Express app with the routes to search and show files (and a simple index) - A
searchWorker.js— which does the actual searching of the files
For brevity, I’ll avoid posting the full code, but UofTCTF publishes challenges on their Github 🔗, so be sure to search there for the actual code!
app.js’s /view/:fileName route is interesting in that it has this condition:
if (!fileData?.visible) {
return res.status(404).send('File not found or inaccessible.');
}How is visible determined? Only the flag.txt file is not visible:
function initializeFiles() {
const files = fs.readdirSync(CODE_SAMPLES_DIR);
files.forEach(file => {
filesIndex[file] = {
visible: file !== 'flag.txt',
path: path.join(CODE_SAMPLES_DIR, file),
name: file,
language: LANG_MAP[path.extname(file)] || null
};
});
console.log(chalk.green('Initialized file index.'));
}The /search route has no implementation of interest, so let’s dig into searchWorker.js.
As a spoiler, this is the key file, so I’ll actually put up all the code:
// searchWorker.js
import { parentPort, workerData } from 'worker_threads';
import fs from 'fs';
function handleRegexSearch(content, regex) {
const matches = Array.from(content.matchAll(regex));
return matches.map(match => ({
start: match.index,
end: match.index + match[0].length
}));
}
function handleNormalSearch(content, searchTerm) {
const matches = [];
let idx = content.toLowerCase().indexOf(searchTerm);
while (idx !== -1) {
matches.push({
start: idx,
end: idx + searchTerm.length
});
idx = content.toLowerCase().indexOf(searchTerm, idx + searchTerm.length);
}
return matches;
}
function generatePreview(content, matchIndices, previewLength) {
if (matchIndices.length === 0) return null;
const firstMatch = matchIndices[0];
const start = Math.max(firstMatch.start - previewLength, 0);
const end = Math.min(firstMatch.end + previewLength, content.length);
let preview = content.substring(start, end);
const adjustedIndices = matchIndices
.map(match => ({
start: match.start - start,
end: match.end - start
}))
.filter(match => match.start >= 0 && match.end <= preview.length)
.sort((a, b) => b.start - a.start);
adjustedIndices.forEach(match => {
preview =
preview.slice(0, match.start) +
`<mark>${preview.slice(match.start, match.end)}</mark>` +
preview.slice(match.end);
});
return (preview.includes("<mark></mark>")) ? null : preview;
}
const { filesIndex, language, searchRegex, searchTerm, PREVIEW_LENGTH } = workerData;
const results = Object.entries(filesIndex)
.filter(([fileName, fileData]) => {
if (language && language !== 'All') {
return fileData.language === language;
}
return true;
})
.map(([fileName, fileData]) => {
let content;
try {
content = fs.readFileSync(fileData.path, 'utf-8');
} catch (e) {
return null;
}
let matchIndices = [];
if (searchRegex) {
matchIndices = handleRegexSearch(content, searchRegex);
} else if (searchTerm) {
matchIndices = handleNormalSearch(content, searchTerm);
}
if (matchIndices.length === 0) return null;
const preview = generatePreview(content, matchIndices, PREVIEW_LENGTH);
return preview
? {
fileName,
preview,
language: fileData.language,
visible: fileData.visible
}
: null;
})
.filter(result => result !== null && result.visible);
parentPort.postMessage({ results });So this file does a few things:
- Does either a regex search or “contains/indexOf” search
- Generates a preview of what is found
- Only gives visible results
With all the main code covered, it’s important to note that there’s no way to read the flag directly.
It’s not like there’s an HTTP daemon to exploit — Node.js/Express is serving the traffic.
There are two routes that show file contents: the one that shows full files and the one that shows search previews;
however, they both filter out !visible files, so they can’t be used to read the flag.
The key to the solution is that the filtering of search results is done at the end —
after all the files have been searched (JavaScript’s .map/.filter/etc all produce arrays, as opposed to iterators),
and certain regex engines are prone to what is known as catastrophic backtracking.
Perhaps to delve a bit on catastrophic backtracking (feel free to skip)…
Regex has these things known as greedy quantifiers, and the most well-known ones are + and * —
1 or more characters, and 0 or more characters, respectively.
While they can be made lazy by appending a ?,
they are greedy without the question mark and will match as many characters as they can.
If the next part of the match fails, the regex engine will backtrack to the greedy quantifier and match one less character.
And so on.
Depending on the string and its length, catastrophic backtracking can take up lots of time and CPU usage —
hence the catastrophic nature of it.
This is why it’s often recommended to not evaluate user-provided regex (DoS),
why it’s recommended add a timeout when evaluating (user-provided) regex,
and one reason why non-backtracking regex engines like re2 exist.
JavaScript is a backtracking regex engine, so it is prone to catastrophic backtracking. Let’s take this regex (that we’ll use in a bit) as an example:
/^(.+)*\xff/Stacking greedy quantifiers (the + and *) like this is a classic way to trigger catastrophic backtracking.
Let’s suppose we have a string that doesn’t have a \xff, like 123456789.
- First, the (.+) is greedily evaluated and will match the entire string. The * has matched once (the prior capture group), and it will try again. It will fail, but this is fine as none need to match. The \xff fails to match.
- The engine backtracks 1 character.
12345678 gets matched in the first capture group.
The * allows the capture group to again match the final 9.
We’re at the end, and there’s no \xff.
The engine backtracks 1 character.
The final 9 is not
\xff. - The engine backtracks one character. 1234567 gets matched. 89 then gets matched. We’re at the end without \xff. Backtrack once. 8 gets matched. Then 9. At end without \xff. Backtrack once. 9 is not \xff. Backtrack once. 8 is not \xff.
- Backtrack once. 123456 gets matched. …
I’m just going to give up, and one can perhaps see how time-consuming this is getting! This is what we’ll take advantage of.
Ah, also of note is that there is a LANG_MAP dictionary that does not include .txt files. To avoid catastrophically backtracking every non-flag file…
Exploit
Let’s start with this regex:
/^uoftctf\{([a-z]|(.+)*\xff)/By starting off with uoftctf\{,
we can avoid performing the catastrophic backtracking portion on the files we don’t care about.
The key part is in this capture group:
(
[a-z] # what's effectively a binary search -- to whittle down the next character
|
(.+)*\xff # the catastrophic backtracking implementation
)If we search for that regex, it completes in 125ms or so.
Then we change the character class to [a-m].
This suddenly and reliably takes over 1s to run, so we appear to be catastrophically backtracking.
Now [n-s] — 1s. Now [t-v] — 1s. Now [wx] — 125ms! Now [w] — 125ms!
Certain character classes took a long time because they failed to match,
and the alternation (aka the | operator) then tries the catastrophic backtracking part.
If we successfully match, no catastrophic backtracking.
The first character appears to be w, and our regex becomes:
/^uoftctf\{(w[a-z]|(.+)*\xff)/And we just keep going!
To keep the example simple, I started with [a-z],
but, since numbers and special characters are also possible,
[\x20-\x7e] is a better initial range (or, rather, half of it).
Instead of scripting it out, I did it manually because I correctly suspected it would be quicker this way.
It was easy to guess subsequent characters because the flag is an English sentence.
Eventually, we know we’ve reached the end when, after adding the next character, we no longer can cause catastrophic backtracking. The final regex ends up being…
/^uoftctf\{(why_15_my_4pp_l4661n6_50_b4dly\?\?[\x7d]|(.+)*\xff)/So guess what the flag is (👉゚ヮ゚)👉